| 2019 and 2020 | ||
|---|---|---|
| P. Henderson Advances in Scene Understanding: Object Detection, Reconstruction, Layouts, and Inference PhD thesis, 2019. | ||
 | P. Henderson, V. Ferrari Learning single-image 3D reconstruction by generative modelling of shape, pose and shading International Journal of Computer Vision (IJCV), 128(4), pp. 835-854, April 2020. Also available on arXiv | |
| 2018 | ||
| H. Caesar Restoring the balance between stuff and things in scene understanding PhD thesis, 2018. | ||
 | P. Henderson, V. Ferrari Learning to Generate and Reconstruct 3D Meshes with only 2D Supervision British Machine Vision Conference (BMVC), Newcastle, September 2018 (oral) Code for DIRT, our fast differentiable mesh renderer for TensorFlow Also available on arXiv | |
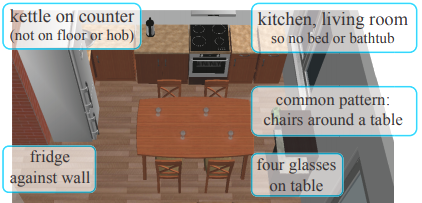 | P. Henderson, K. Subr, V. Ferrari Automatic Generation of Constrained Furniture Layouts arXiv preprint, August 2018. | |
 | H. Caesar, J. Uijlings, V. Ferrari COCO-Stuff: Thing and Stuff Classes in Context IEEE Computer Vision and Pattern Recognition (CVPR), Salt Lake City, June 2018. Dataset Also available on arXiv | |
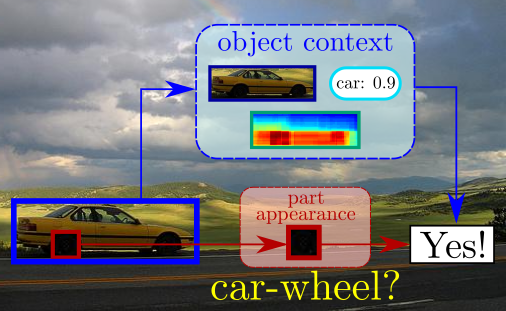 | A. Gonzalez-Garcia, D. Modolo, V. Ferrari Objects as Context for Detecting Their Semantic Parts IEEE Computer Vision and Pattern Recognition (CVPR), Salt Lake City, June 2018. Also available on arXiv | |
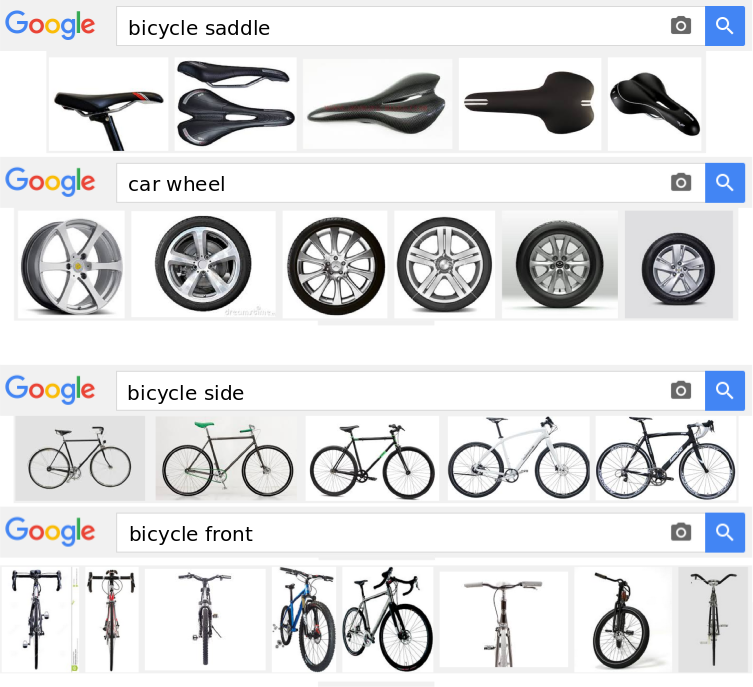 | D. Modolo, V. Ferrari Learning Semantic Part-Based Models from Google Images IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 40(6), pp. 1502-1509, June 2018 Also available on arXiv | |
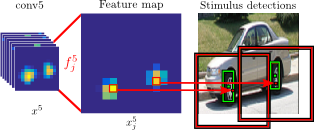 | A. Gonzalez-Garcia, D. Modolo, V. Ferrari Do Semantic Parts Emerge in Convolutional Neural Networks? International Journal of Computer Vision (IJCV), 126(5), pp. 476-494, May 2018. Also available on arXiv | |
| 2017 | ||
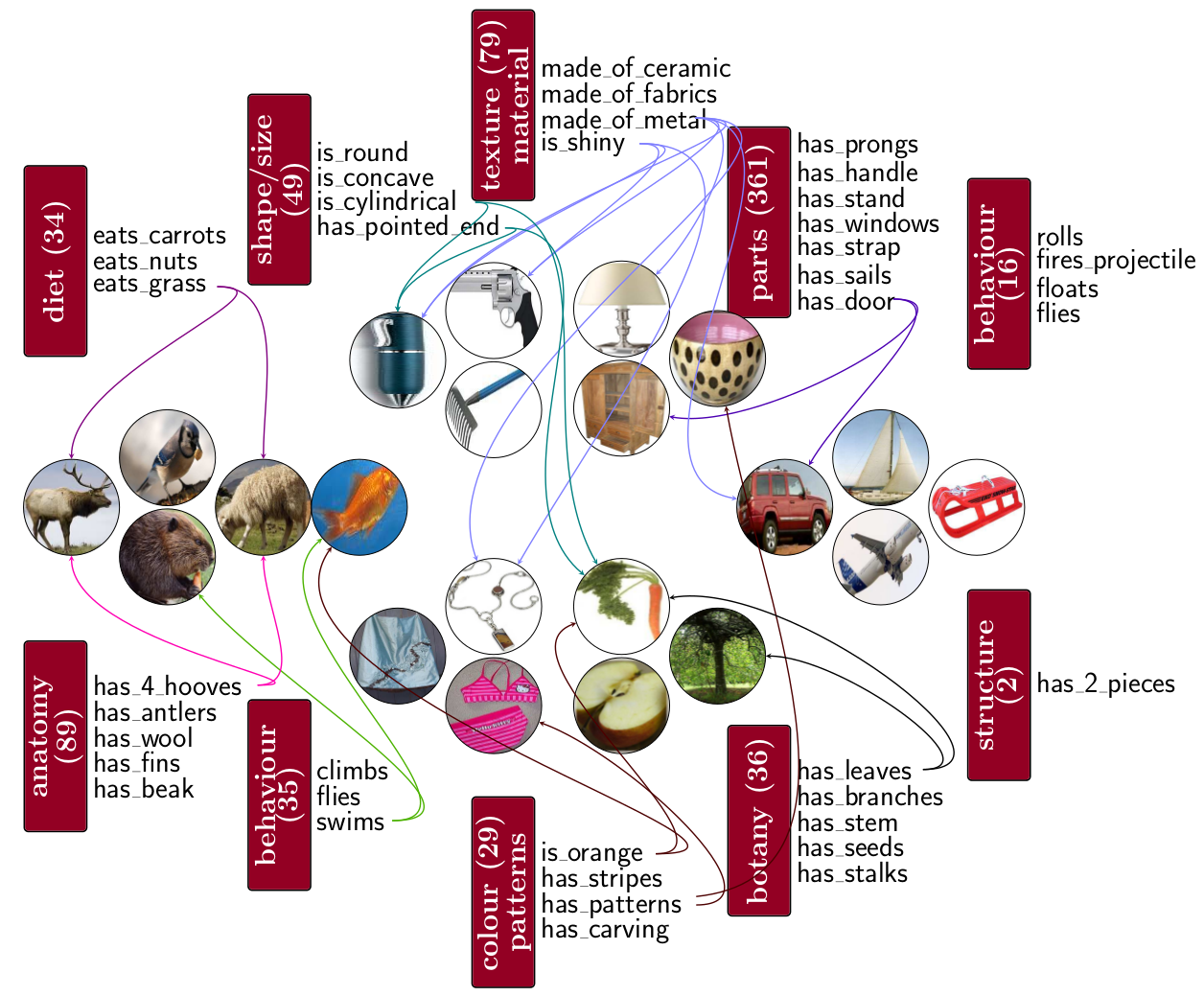 | C. Silberer, V. Ferrari, M. Lapata Visually Grounded Meaning Representations IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 39(11), 2284-2297, November 2017. | |
 | D. P. Papadopoulos Efficient human annotation schemes for training object class detectors PhD thesis, 2017. | |
| V. Kalogeiton Localizing spatially and temporally objects and actions in videos PhD thesis, 2017. | ||
| A. Gonzalez-Garcia Image context for object detection, object context for part detection PhD thesis, 2017. | ||
 | D. P. Papadopoulos, J. R. R. Uijlings, F. Keller and V. Ferrari Extreme clicking for efficient object annotation International Conference on Computer Vision (ICCV), Venice, Italy, October 2017. Supplementary material Also available on arXiv Download extreme clicks (PASCAL VOC 2007 and 2012) | |
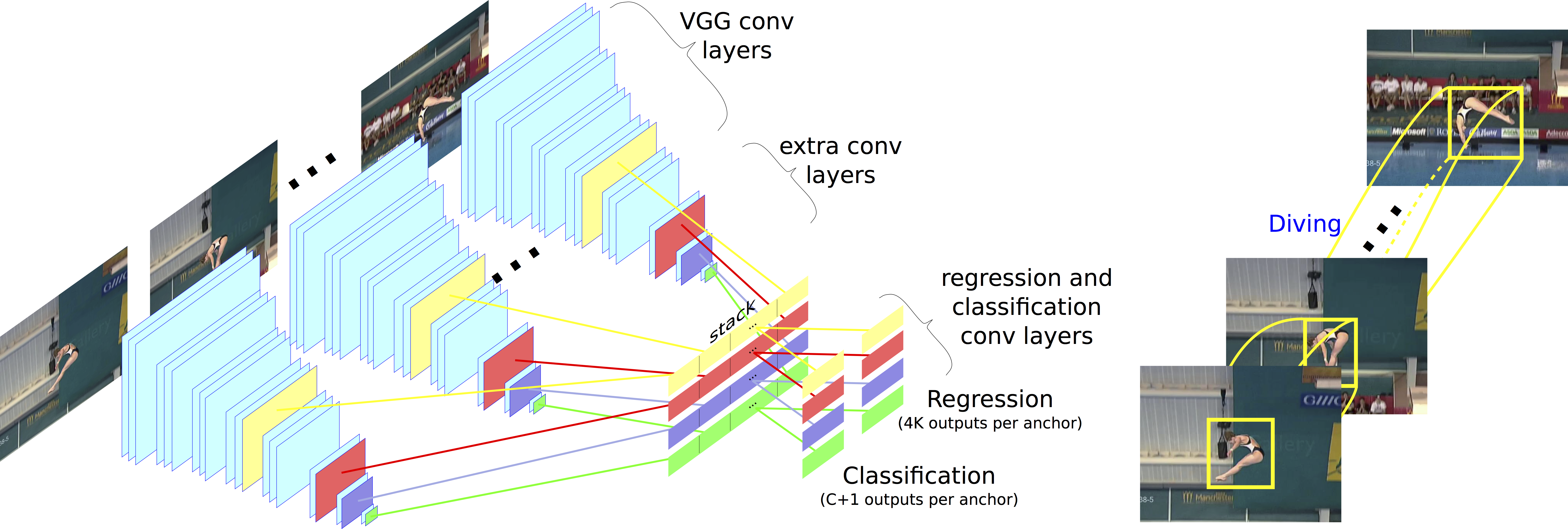 | V. Kalogeiton, P. Weinzaepfel, V. Ferrari and C. Schmid Action Tubelet Detector for Spatio-Temporal Action Localization International Conference on Computer Vision (ICCV), Venice, Italy, October 2017. Poster Project page Extended version available on arXiv | |
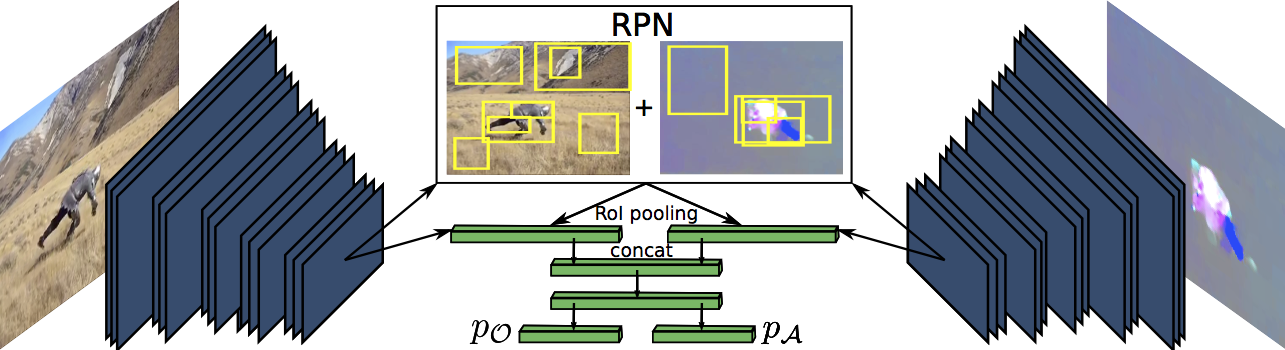 | V. Kalogeiton, P. Weinzaepfel, V. Ferrari and C. Schmid Joint learning of object and action detectors International Conference on Computer Vision (ICCV), Venice, Italy, October 2017. Poster Project page | |
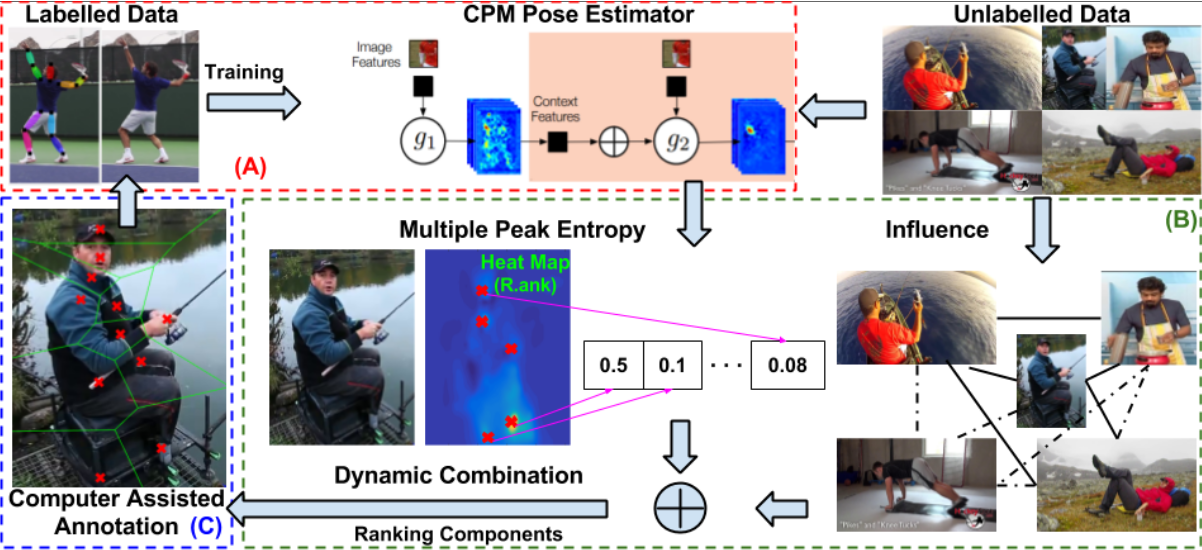 | B. Liu and V. Ferrari Active Learning for Human Pose Estimation International Conference on Computer Vision (ICCV), Venice, Italy, October 2017. | |
 | M. Shi, H. Caesar, V. Ferrari Weakly Supervised Object Localization Using Things and Stuff Transfer International Conference on Computer Vision (ICCV), Venice, Italy, October 2017. Supplementary material Also available on arXiv | |
 | D. P. Papadopoulos, J. R. R. Uijlings, F. Keller and V. Ferrari Training object class detectors with click supervision IEEE Computer Vision and Pattern Recognition (CVPR), Honolulu, Hawaii, July 2017. (spotlight oral) Project page with data Spotlight video at CVPR 2017 Creative AI podcast interview Also available on arXiv | |
 | L. Del Pero, S. Ricco, R. Sukthankar, V. Ferrari Behavior Discovery and Alignment of Articulated Object Classes from Unstructured Video International Journal of Computer Vision (IJCV), 121(2), p. 303-325, January 2017. Project page Dataset Also available on arXiv | |
| 2016 | ||
| D. Modolo Advances in detecting object classes and their semantic parts PhD thesis, 2016. | ||
| A. Papazoglou Video object segmentation and applications in temporal alignment and aspect learning PhD thesis, 2016. | ||
 | P. Henderson, V. Ferrari End-to-end training of object class detectors for mean average precision Asian Conference on Computer Vision (ACCV), Taipei, Taiwan, November 2016. Also available on arXiv | |
 | A. Papazoglou, L. Del Pero and V. Ferrari Video temporal alignment for object viewpoint Asian Conference on Computer Vision (ACCV), Taipei, Taiwan, November 2016. Dataset | |
  | V. Kalogeiton, V. Ferrari and C. Schmid Analysing domain shift factors between videos and images for object detection IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 38(11), pp. 2327-2334, November 2016 Youtube-Objects dataset v 2.3 Project page Explore Also available on arXiv | |
 | A. Bearman, O. Russakovsky, V.Ferrari and L. Fei-Fei What's the point: Semantic segmentation with point supervision European Conference on Computer Vision (ECCV), Amsterdam, Netherlands, October 2016. Project page with data Also available on arXiv | |
 | P. Henderson and V. Ferrari Automatically selecting inference algorithms for discrete energy minimisation European Conference on Computer Vision (ECCV), Amsterdam, Netherlands, October 2016. Also available on arXiv | |
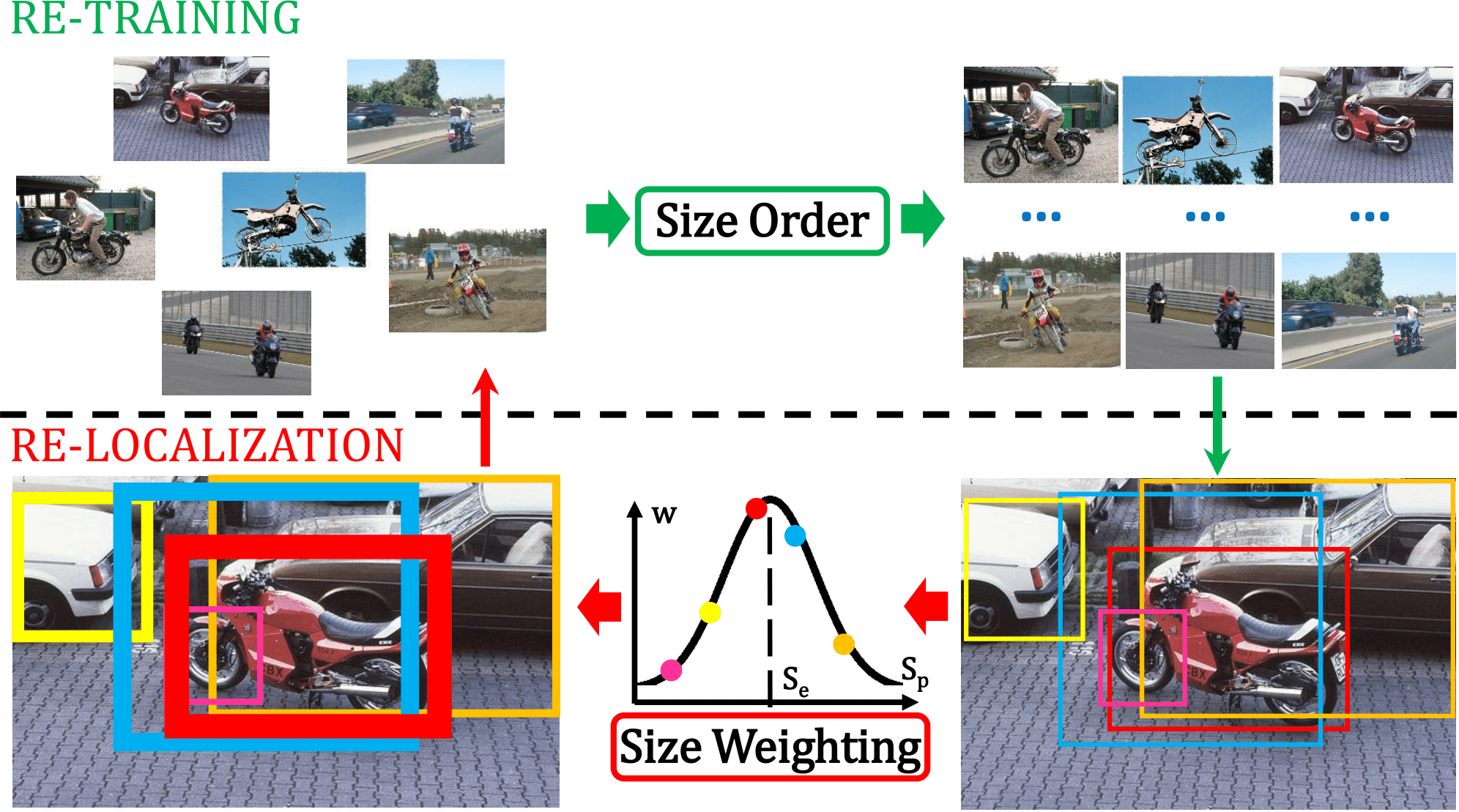 | M. Shi, V. Ferrari Weakly Supervised Object Localization Using Size Estimates European Conference on Computer Vision (ECCV), Amsterdam, Netherlands, October 2016. Also available on arXiv | |
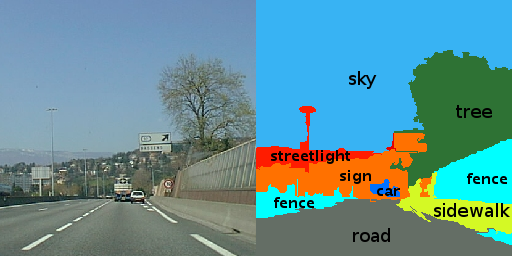 | H. Caesar, J. Uijlings, V. Ferrari Region-based semantic segmentation with end-to-end training European Conference on Computer Vision (ECCV), Amsterdam, Netherlands, October 2016. Source code and trained models Also available on arXiv | |
 | A. Papazoglou, L. Del Pero and V. Ferrari Discovering object aspects from video Image and Vision Computing, 52(C), pp. 206-217, August 2016 Dataset | |
 | L. Del Pero, S. Ricco, R. Sukthankar, V. Ferrari Discovering the physical parts of an articulated object class from multiple videos IEEE Computer Vision and Pattern Recognition (CVPR), Las Vegas, June 2016. Project page with dataset An article on TechCrunch about this work | |
 | R. T. Ionescu, B. Alexe, M. Leordeanu, M. Popescu, D. P. Papadopoulos, V. Ferrari How hard can it be? Estimating the difficulty of visual search in an image IEEE Computer Vision and Pattern Recognition (CVPR), Las Vegas, June 2016. Project page with data and code | |
 | D. P. Papadopoulos, J. R. R. Uijlings, F. Keller and V. Ferrari We don't need no bounding-boxes: Training object class detectors using only human verification IEEE Computer Vision and Pattern Recognition (CVPR), Las Vegas, June 2016. (spotlight oral) Also available on arXiv | |
| 2015 | ||
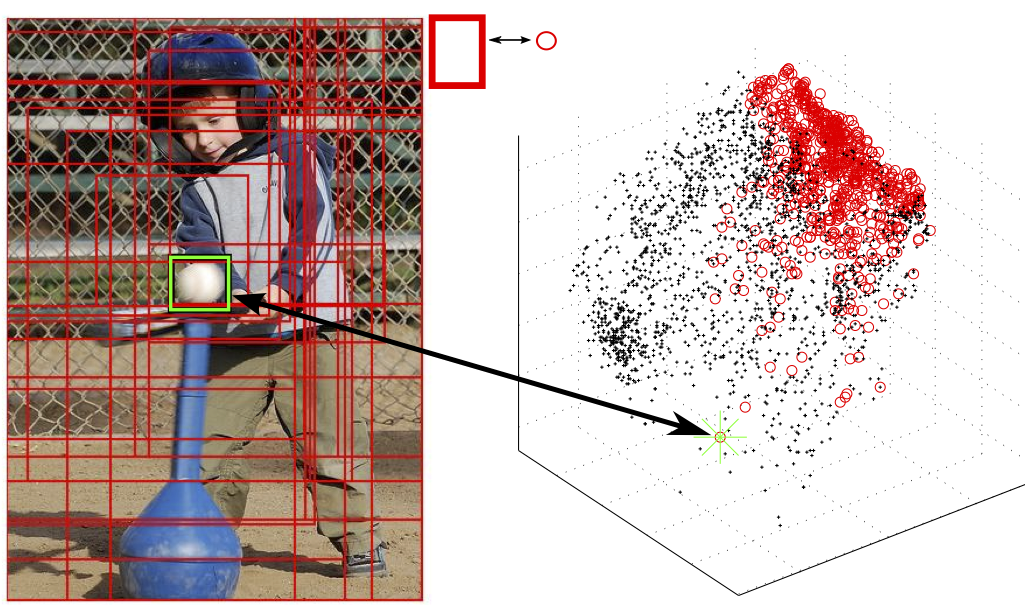 | A. Vezhnevets and V. Ferrari Object localization in ImageNet by looking out of the window British Machine Vision Conference (BMVC), Swansea, September 2015. Also available on arXiv | |
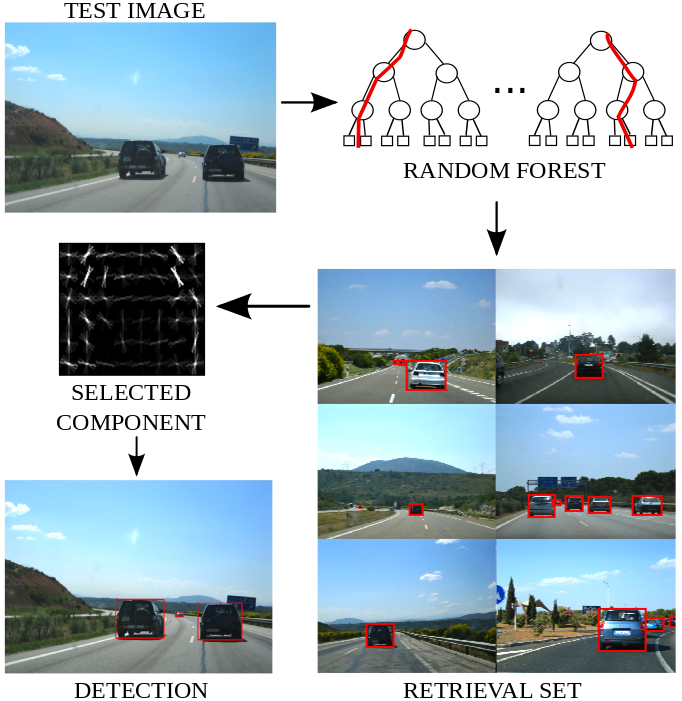 | D. Modolo, A. Vezhnevets, and V. Ferrari Context Forest for Object Class Detection British Machine Vision Conference (BMVC), Swansea, September 2015. (oral) Earlier version available on arXiv | |
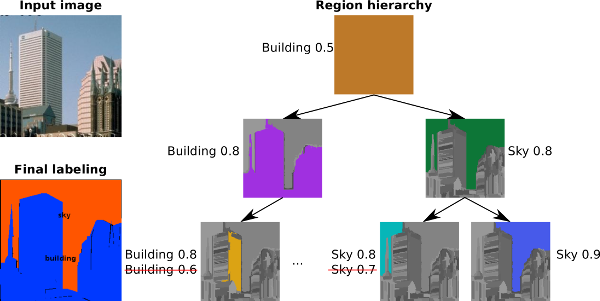 | H. Caesar, J. Uijlings and V. Ferrari Joint Calibration for Semantic Segmentation British Machine Vision Conference (BMVC), Swansea, September 2015. Update Aug 2015: Added VGG16 experiments which greatly improves results Also available on arXiv | |
 | M. Volpi and V. Ferrari Semantic segmentation of urban scenes by learning local class interactions IEEE Computer Vision and Pattern Recognition Workshops (CVPRW) "EARTHVISION", Boston, June 2015. (Best Paper Award) Dataset page | |
 | L. Del Pero, S. Ricco, R. Sukthankar and V. Ferrari Articulated Motion Discovery using Pairs of Trajectories IEEE Computer Vision and Pattern Recognition (CVPR), Boston, June 2015. Project page TigDog Dataset V 1.0 Also available on arXiv | |
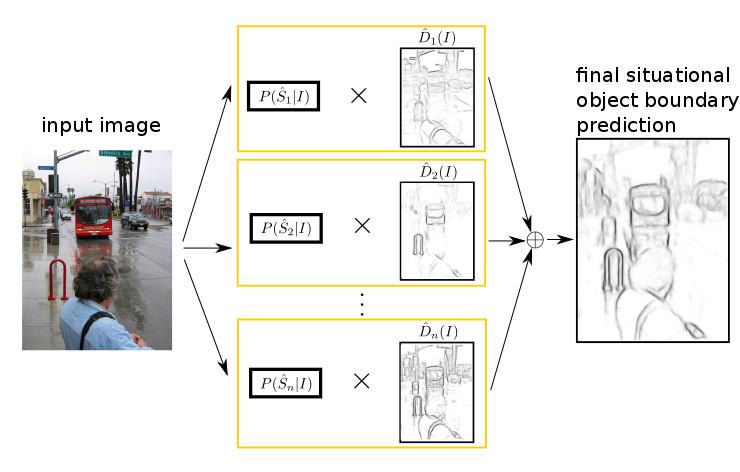 | J.R.R. Uijlings and V. Ferrari Situational Object Boundary Detection IEEE Computer Vision and Pattern Recognition (CVPR), Boston, June 2015. (oral) Also available on arXiv | |
 | A. Gonzalez-Garcia, A. Vezhnevets and V. Ferrari An Active Search Strategy for Efficient Object Class Detection IEEE Computer Vision and Pattern Recognition (CVPR), Boston, June 2015. Also available on arXiv | |
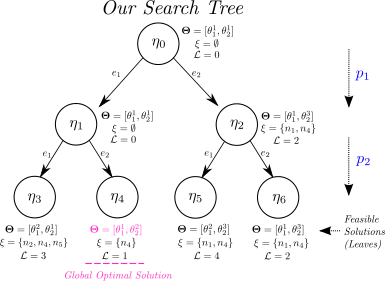 | D. Modolo, A. Vezhnevets, O. Russakovsky and V. Ferrari Joint calibration of Ensemble of Exemplar SVMs IEEE Computer Vision and Pattern Recognition (CVPR), Boston, June 2015. Also available on arXiv | |
 | M. Volpi and V. Ferrari Structured prediction for urban scene semantic segmentation with geographic context Joint Urban Remote Sensing Event, (JURSE), Lausanne, Switzerland, April 2015. | |
| 2014 | ||
 | M. Guillaumin, D. Kuettel, and V. Ferrari ImageNet Auto-annotation with Segmentation Propagation International Journal of Computer Vision (IJCV), 110(3), p. 328-348, December 2014. Source code for segmentation transfer Project page with data Invited talk at Google | |
 | D. P. Papadopoulos, A. D. F. Clarke, F. Keller and V. Ferrari Training object class detectors from eye tracking data European Conference on Computer Vision (ECCV), Zurich, Switzerland, September 2014. Pascal Objects Eye Tracking Dataset | |
 | A. Kolesnikov, M. Guillaumin, V. Ferrari and C. H. Lampert Closed-Form Approximate CRF Training for Scalable Image Segmentation European Conference on Computer Vision (ECCV), Zurich, Switzerland, September 2014. | |
 | A. Vezhnevets and V. Ferrari Associative embeddings for large-scale knowledge transfer with self-assessment IEEE Computer Vision and Pattern Recognition (CVPR), Columbus, June 2014. Also available on arXiv Project page with data | |
 | M. J. Marin-Jimenez, A. Zisserman, M. Eichner and V. Ferrari Detecting People Looking at Each Other in Videos International Journal of Computer Vision (IJCV), 106(3), p. 282-296, February 2014. | |
| 2013 | ||
 | A. Papazoglou and V. Ferrari Fast object segmentation in unconstrained video International Conference on Computer Vision (ICCV), Sydney, Australia, December 2013 Project page | |
 | D. Kuettel and V. Ferrari Learning to approximate global shape priors for figure-ground segmentation British Machine Vision Conference (BMVC), Bristol, September 2013. (Best poster prize) | |
 | C. Silberer, V. Ferrari and M. Lapata Models of Semantic Representation with Visual Attributes Association for Computational Linguistics (ACL), Sofia, August 2013. | |
 | A. Prest, V. Ferrari, and C. Schmid Explicit modeling of human-object interactions in realistic videos IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 35(4), pp. 835-848, August 2013. This publication is a revised version of the homonymous INRIA technical report that appeared in September 2011. | |
 | M. Guillaumin, L. Van Gool and V. Ferrari Fast Energy Minimization using Learned State Filters IEEE Computer Vision and Pattern Recognition (CVPR), Portland, June 2013. Code | |
| 2012 | ||
 | B. Alexe, N. Heess, Y.W. Teh and V. Ferrari Searching for objects driven by context Advances in Neural Information Processing Systems (NIPS), Nevada, USA, December 2012 (spotlight oral). Sequences of hypotheses generated on Pascal VOC 2010 | |
 | M. Eichner, V. Ferrari Appearance Sharing for Collective Human Pose Estimation Asian Conference on Computer Vision (ACCV), Daejeon, Korea, November 2012. | |
 | N. Jammalamadaka, A. Zisserman, M. Eichner, V. Ferrari, C. V. Jawahar Has my Algorithm Succeeded? An Evaluator for Human Pose Estimators European Conference on Computer Vision (ECCV), Firenze, Italy, October 2012. | |
| D. Kuettel, M. Guillaumin, and V. Ferrari Segmentation Propagation in ImageNet European Conference on Computer Vision (ECCV), Firenze, Italy, October 2012. (BEST PAPER AWARD) Spotlight video at ECCV12 Source code for segmentation transfer Project page with data Invited talk at Google | |
 | A. Prest, C. Schmid, and V. Ferrari Weakly supervised learning of interactions between humans and objects IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), March 2012. | |
 | T. Deselaers, B. Alexe, and V. Ferrari Weakly Supervised Localization and Learning with Generic Knowledge International Journal of Computer Vision (IJCV), 100(3), p. 257-293, September 2012 This publication is a revised version of ETHZ technical report #275 that appeared in August 2011. | |
 | M. Eichner and V. Ferrari Human Pose Co-Estimation and Applications IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 34(11), p. 2282-2288, November 2012. This publication is a revised version of the homonymous ETHZ technical report #277 that appeared in November 2011. Synchronic activities stickmen dataset. | |
 | D. Kuettel and V. Ferrari Figure-ground segmentation by transferring window masks IEEE Computer Vision and Pattern Recognition (CVPR), Providence, June 2012. source code and data | |
 | M. Guillaumin and V. Ferrari Large-scale Knowledge Transfer for Object Localization in ImageNet IEEE Computer Vision and Pattern Recognition (CVPR), Providence, June 2012. Project page with data Invited talk at Google | |
 | A. Prest, C. Leistner, J. Civera, C. Schmid, and V. Ferrari Learning Object Class Detectors from Weakly Annotated Video IEEE Computer Vision and Pattern Recognition (CVPR), Providence, June 2012. Youtube-Objects dataset v 2.0 | |
 | A.Vezhnevets, V. Ferrari, J. M. Buhmann Weakly Supervised Structured Output Learning for Semantic Segmentation IEEE Computer Vision and Pattern Recognition (CVPR), Providence, June 2012. (oral) | |
 | A.Vezhnevets, J. M. Buhmann, V. Ferrari Active Learning for Semantic Segmentation with Expected Change IEEE Computer Vision and Pattern Recognition (CVPR), Providence, June 2012. | |
 | N. Jammalamadaka, A. Zisserman, M. Eichner, V. Ferrari, C. V. Jawahar Video Retrieval by Mimicking Poses International Conference on Multimedia Retrieval (ICMR), Hong Kong, June 2012. | |
 | M. Eichner, M. Marin-Jimenez, A. Zisserman, V. Ferrari 2D Articulated Human Pose Estimation and Retrieval in (Almost) Unconstrained Still Images International Journal of Computer Vision, (IJCV), 99(2), p. 190-214, September 2012 This publication is a revised version of the homonymous ETHZ technical report #272 that appeared in September 2010. | |
 | B. Alexe, T. Deselaers and V. Ferrari Measuring the objectness of image windows IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 34(11), p. 2189-2202, November 2012. This publication is a revised version of the homonymous ETHZ technical report #276 that appeared in August 2011. Source code v2.2 | |
| D. Kuettel, M. Guillaumin, and V. Ferrari Combining Image-Level and Segment-Level Models for Automatic Annotation 18th International Conference on MultiMedia Modelling (MMM), Klagenfurt, Austria, January, 2012. (oral) | ||
| 2011 | ||
 | B. Alexe, V. Petrescu, and V. Ferrari Exploiting spatial overlap to efficiently compute appearance distances between image windows Advances in Neural Information Processing Systems (NIPS), Granada, December 2011. Supplementary material Source code v1.0 | |
 | A. Vezhnevets, V. Ferrari, and J. Buhmann Weakly Supervised Semantic Segmentation with a Multi-image Model International Conference on Computer Vision (ICCV), Barcelona, Spain, November 2011 | |
 | M. Marin-Jimenez, A. Zisserman, and V. Ferrari "Here's looking at you, kid" - Detecting people looking at each other in videos British Machine Vision Conference (BMVC), Dundee, September 2011. (oral) Data annotations | |
 | M. Ozcan, L. Jie, V. Ferrari, and B. Caputo A Large-Scale Database of Images and Captions for Automatic Face Naming British Machine Vision Conference (BMVC), Dundee, September 2011. (oral) FAN-Lage database of 125000 images and captions | |
 | L. Jie, O. Francesco, C. Barbara, and V. Ferrari Learning from Images with Captions Using the Maximum Margin Set Algorithm IDIAP Research Report #30, August 2011 (submitted to PAMI). | |
 | T. Deselaers and V. Ferrari Visual and Semantic Similarity in ImageNet IEEE Computer Vision and Pattern Recognition (CVPR), Colorado Springs, June 2011. | |
| 2010 | ||
 | T. Deselaers, B. Alexe, and V. Ferrari Localizing Objects while Learning Their Appearance European Conference on Computer Vision (ECCV), Crete, Greece, September 2010. (oral) This publication is also ETH technical report #274. | |
 | B. Alexe, T. Deselaers, and V. Ferrari ClassCut for Unsupervised Class Segmentation European Conference on Computer Vision (ECCV), Crete, Greece, September 2010. | |
 | M. Eichner and V. Ferrari We Are Family: Joint Pose Estimation of Multiple Persons European Conference on Computer Vision (ECCV), Crete, Greece, September 2010. supplementary material Dataset | |
 | T. Deselaers and V. Ferrari A Conditional Random Field for Multiple-Instance Learning International Conference on Machine Learning (ICML), Haifa, Israel, June 2010. Paper discussion site | |
 | B. Alexe, T. Deselaers, and V. Ferrari What is an object? IEEE Computer Vision and Pattern Recognition (CVPR), San Francisco, June 2010. Source code v2.2 | |
 | D. Kuettel, M. Breitenstein, L. van Gool, and V. Ferrari What's going on? Discovering Spatio-Temporal Dependencies in Dynamic Scenes IEEE Computer Vision and Pattern Recognition (CVPR), San Francisco, June 2010. (oral) Project page with data An article about this work in the eth life magazine available in english and german. A short article in the german M.I.T. magazine of 2010/8, see preview or original content (paywalled). | |
 | T. Deselaers and V. Ferrari Global and Efficient Self-Similarity for Object Classification and Detection IEEE Computer Vision and Pattern Recognition (CVPR), San Francisco, June 2010. (oral) Video of the talk at CVPR 2010 Code available | |
 | B. Alexe, T. Deselaers, M. Eichner, V. Ferrari, P. Gehler, A. Lehmann, S. Pellegrini, A. Prest Which Energy Minimization for my MRF/CRF? A Cheat-Sheet Computer Vision Laboratory, ETH Zurich, Technical Report 273 | |
 | V. Ferrari, F. Jurie, and C. Schmid From Images to Shape Models for Object Detection International Journal of Computer Vision (IJCV), March 2010. Learning explicit shape models from unsegmented training images, and using them to localize object outlines in novel test images. Performance plots available as Matlab figures Matlab source code v1.3 This publication is a revised version of the homonymous INRIA technical report appeared in July 2008 (now obsolete and no longer available). | |
| 2009 | ||
 | L. Jie, B. Caputo, and V. Ferrari Who's Doing What: Joint Modeling of Names and Verbs for Simultaneous Face and Pose Annotation Advances in Neural Information Processing Systems (NIPS), Vancouver, December 2009. Associating persons' faces and poses in news images to names and verbs in their captions. | |
 | M. Eichner and V. Ferrari Better Appearance Models for Pictorial Structures British Machine Vision Conference (BMVC), London, September 2009. (oral) Estimating body part appearance models from a single image of an unknown person. ETHZ PASCAL Stickmen dataset of annotated 2D human poses Pose estimation results Matlab source code | |
 | A. Thomas, V. Ferrari, B. Leibe, T. Tuytelaars, L. Van Gool Using Multi-view Recognition to Guide a Robot's attention International Journal of Robotics Research (IJRR), August 2009. Multi-view object class detection and meta-data inference (this journal paper is an extended version of our CVPR 2006 and RSS 2008 papers) | |
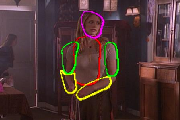 | V. Ferrari, M. Marin, and A. Zisserman 2D Human Pose Estimation in TV Shows Dagstuhl post-proceedings, 2009. Fully automatic 2D human pose estimation in uncontrolled video. This is an extension of our CVPR 2008 paper. | |
 | A. Thomas, V. Ferrari, B. Leibe, T. Tuytelaars, L. Van Gool Shape-from-recognition: Recognition enables meta-data transfer Computer Vision and Image Understanding (CVIU), December 2009. Inferring meta-data, such as depth, surface normals, and part decomposition from a single image of an object, using cognitive feeback from recognition (this journal paper is an extended version of our 3dRR 2007 paper) | |
 | V. Ferrari, M. Marin, and A. Zisserman Pose Search: retrieving people using their pose IEEE Computer Vision and Pattern Recognition (CVPR), Miami, June 2009. (oral) Retrieving shots containing a particular human pose from movies and TV videos. Buffy Pose Classes dataset for pose search Showcase page | |
publications by V. Ferrari before CALVIN | ||
| 2008 | ||
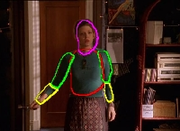 | V. Ferrari, M. Marin, and A. Zisserman Progressive Search Space Reduction for Human Pose Estimation IEEE Computer Vision and Pattern Recognition (CVPR), Alaska, June 2008. Fully automatic 2D human pose estimation in uncontrolled video (Buffy the Vampire Slayer!). Buffy Stickmen dataset of annotated 2D human poses Software for detecting and tracking human upper-bodies Showcase page | |
 | A. Thomas, V. Ferrari, B. Leibe, T. Tuytelaars, L. Van Gool Using Recognition to Guide a Robot's Attention Robotics: Science and Systems Conference (RSS), Zurich, Switzerland, June 2008. (oral) Recognizing objects of interest for a robot, and localizing interaction points | |
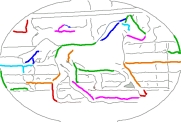 | V. Ferrari, L. Fevrier, F. Jurie, and C. Schmid Groups of Adjacent Contour Segments for Object Detection IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), January 2008 A new family of local contour features and their application to object class detection. Matlab source code v1.05 Source code available on request Performance plots available as Matlab figures This publication is a revised version of the homonymous INRIA technical report appeared in September 2006 (now obsolete and no longer available). | |
| 2007 | ||
 | V. Ferrari and A. Zisserman Learning Visual Attributes Advances in Neural Information Processing Systems (NIPS), Vancouver, December 2007 (spotlight) Weakly supervised learning of visual attributes, such as 'red' and 'striped'. Dataset Showcase page | |
 | A. Thomas, V. Ferrari, B. Leibe, T. Tuytelaars, and L. Van Gool Depth-From-Recognition: Inferring Meta-data by Cognitive Feedback 3D Representation for Recognition (3dRR) - Workshop in conjunction with International Conference on Computer Vision (ICCV), Rio de Janeiro, Brasil, October 2007 Inferring 3D depth from a single image of an object, using cognitive feeback from recognition | |
 | T. Quack, V. Ferrari, B. Leibe, and L. Van Gool Efficient Mining of Frequent and Distinctive Feature Configurations International Conference on Computer Vision (ICCV), Rio de Janeiro, Brasil, October 2007 Feature selection for object class detection, by efficient mining of frequent and distinctive spatial feature configurations | |
 | J. Philbin, O. Chum, J. Sivic, V. Ferrari, M. Marin, A. Bosch, N. Apostolof, and A. Zisserman Oxford TRECVid 2007 - Notebook paper | |
 | V. Ferrari, F. Jurie, and C. Schmid Accurate Object Detection with Deformable Shape Models Learnt from Images IEEE Computer Vision and Pattern Recognition (CVPR), Minneapolis, June 2007. Performance plots available as Matlab figures Matlab source code v1.3 | |
 | V. Ferrari, T. Tuytelaars, and L. Van Gool Simultaneous Object Recognition and Segmentation by Image Exploration Lecture notes in computer science, vol. 4170, (Toward category-level object recognition, eds. J. Ponce, M. Hebert, C. Schmid, and A. Zisserman), pp. 151-178, 2006 Book chapter in a survey of state-of-the-art object recognition methods. Source code v1.1 | |
 | T. Quack, V. Ferrari, and L. Van Gool Video Mining with Frequent Itemset Configurations International Conference on Image and Video Retrieval (CIVR), Arizona, July 2006. | |
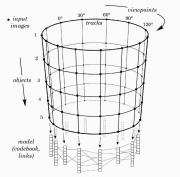 | A. Thomas, V. Ferrari, B. Leibe, T. Tuytelaars, B. Schiele, and L. Van Gool Towards Multi-View Object Class Detection IEEE Computer Vision and Pattern Recognition (CVPR), New York, June 2006. Multi-view object class detection by combining my Image Exploration technique with Leibe`s Implict Shape Model. | |
 | V. Ferrari, T. Tuytelaars, and L. Van Gool Object Detection by Contour Segment Networks European Conference on Computer Vision (ECCV), Graz, May 2006. (oral) Detecting object classes in real images, given a single hand-drawn example as model of their shape. Performance plots available as Matlab figures ETHZ Shape Classes v1.2 dataset (including our performance plots as matlab figures) | |
 | V. Ferrari, T. Tuytelaars, and L. Van Gool Simultaneous Object Recognition and Segmentation from Single or Multiple Model Views International Journal of Computer Vision (IJCV), April 2006 Special issue with extended versions of 5 papers selected from ECCV 2004; also includes material from the CVPR 2004 paper. Source code v1.1 | |
| 2005 | ||
 | H. Bay, V. Ferrari, L. Van Gool Wide-baseline Stereo Matching with Line Segments IEEE Computer Vision and Pattern Recognition (CVPR), San Diego, USA, June 2005 | |
 | A. Zalesny, V. Ferrari, G. Caenen, and L. Van Gool Composite Texture Synthesis International Journal of Computer Vision (IJCV), 62:1-2, pp. 161-176, April 2005 | |
| 2004 | ||
 | Vittorio Ferrari, Tinne Tuytelaars, Luc Van Gool Retrieving Objects From Videos Based on Affine Regions European Signal Processing conference (EUSIPCO), Vienna, Austria, September 2004 (oral) | |
 | Vittorio Ferrari, Tinne Tuytelaars, Luc Van Gool Integrating Multiple Model Views for Object Recognition IEEE Computer Vision and Pattern Recognition (CVPR), Washington, USA, June 2004 Source code v1.1 | |
| Vittorio Ferrari, Tinne Tuytelaars, Luc Van Gool Simultaneous Object Recognition and Segmentation by Image Exploration European Conference on Computer Vision (ECCV), Prague, May 2004. (oral) ETHZ Toys dataset Source code v1.1 | |
| 2003 | ||
 | H. Shao, T. Svoboda, V. Ferrari, T. Tuytelaars, L. Van Gool Fast indexing for image retrieval based on local appearance with re-ranking International Conference on Image Processing (ICIP), September 2003. (oral) | |
 | Vittorio Ferrari, Tinne Tuytelaars, Luc Van Gool Wide-baseline muliple-view Correspondences IEEE Computer Vision and Pattern Recognition (CVPR), Madison, USA, June 2003 | |
| 2002 | ||
 | L. Van Gool, T. Tuytelaars, V. Ferrari, C. Strecha, J. Vanden Wyngaerd and M. Vergauwen 3D Modeling and Registration Under Wide Baseline Conditions Proc. ISPRS Commission III, Vol.~34, Part 3A, Photogrammetric Computer Vision (PCV), Graz, September 2002, pp.~3-14 Invited Keynote speech | |
 | Alexey Zalesny, Vittorio Ferrari, Geert Caenen, Dominik Auf der Maur, and Luc Van Gool Composite Texture Descriptions European Conference on Computer Vision (ECCV), Copenhagen, Danemark, May 2002, Vol. 3, pp. 180-194 | |
 | Geert Caenen, Vittorio Ferrari, Alexey Zalesny, and Luc Van Gool Analyzing the layout of composite textures Texture 2002 Workshop in conjunction with ECCV, Copenhagen, Danemark, May 2002, pp. 15-19. | |
 | Alexey Zalesny, Vittorio Ferrari, Geert Caenen, and Luc Van Gool Parallel Composite Texture Synthesis Texture 2002 Workshop in conjunction with ECCV, Copenhagen, Danemark, May 2002, pp. 151-155. | |
| 2001 | ||
 | Vittorio Ferrari, Tinne Tuytelaars and Luc Van Gool Real-time Affine Region Tracking and Coplanar Grouping in Proc. of the IEEE Computer Vision and Pattern Recognition (CVPR), Kauai, Hawaii, December 2001. |
{kind=link}